Collaboration#
One of the best aspects of XetHub is the ability to collaborate with others.
A standard machine learning solution architecture looks something like this:
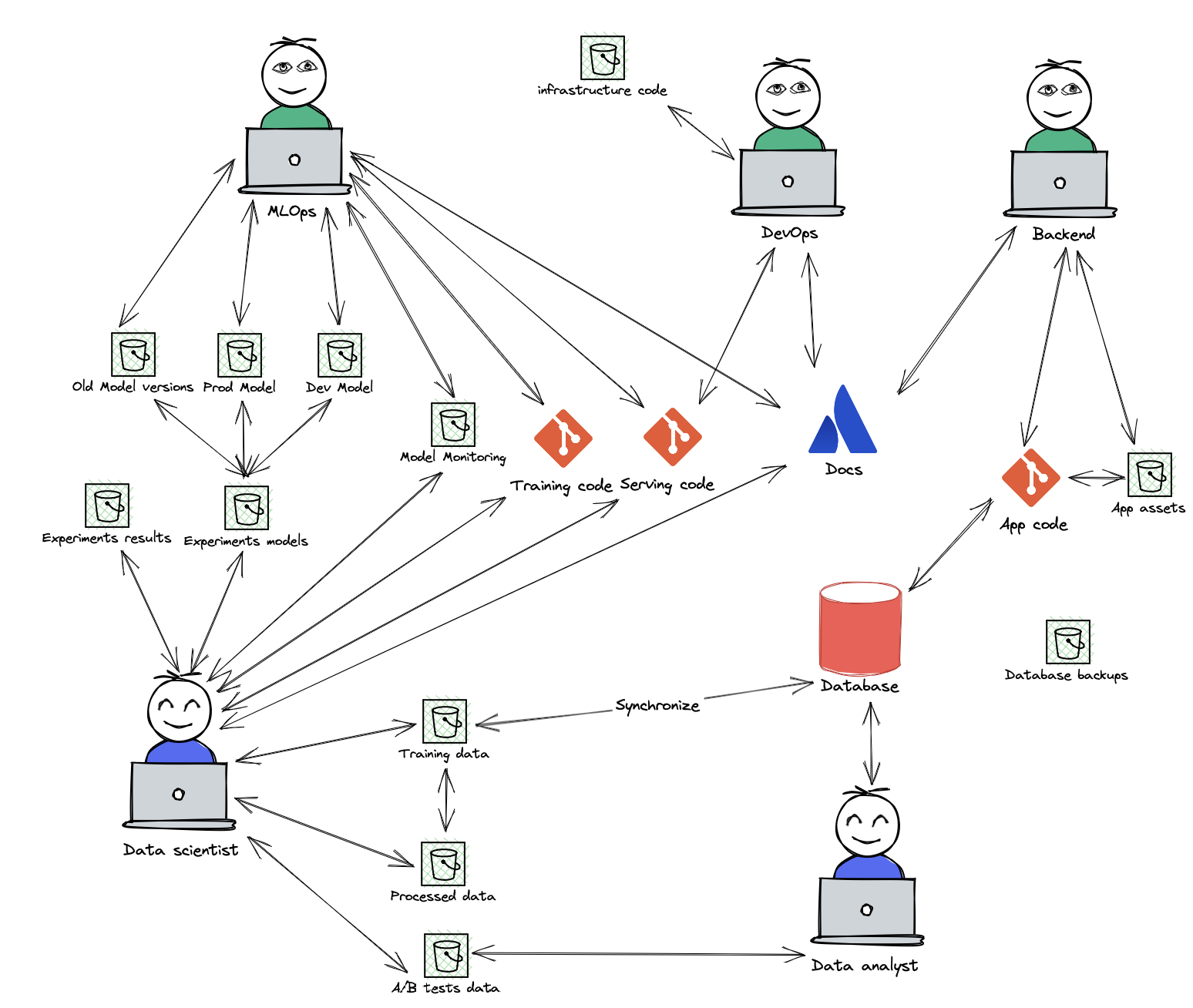
Every team member needs to know the addresses of all the relevant S3 buckets and the credentials to access them.
Different versions of models would be saved in different files with many replicates, and dev and prod models would probably be managed separately.
Monitoring is often done in another bucket, and the data would be copied to a different bucket or database for analysis.
Training data will be append-only, and cleaning and ETL would be directories in buckets with many data copies.
For ML Experiments, another bucket, and as best practice, each would have a snapshot of the data somewhere for reproducibility.
Since serving code depends greatly on the model and technologies, the data scientist and MLOps engineer would have friction to overcome on every code change.
When the data distribution or model assumptions change, or there are any other data related changes, more friction is introduced.
Can we do better? Yes!

Addresses are simply directories and files.
Versions are managed with Git instead of addresses.
This lets a whole team collaborate on a single project–sharing data, models, and code without friction. Everyone can post issues with links to code, revert models, and even revert data issues.
On any given branch, there is a single model file. Whether the branch is for production, development, or experimentation, the entire app just works. No messy managed addresses needed.